Intro

I am Data Engineer having a background as Software engineering with more than 16 years of Industry experience.
Technology is a tool to drive our vision, make our life better. More we are using technology we are generating more data.
To get more insights, values from high volume of data I found much interest working as Big Data professional as following:
* Design Solution architecture for Data driven services
* Implement realtime streaming and batch processing big data services
* Bring Software engineering best practices in Data engineering
* Productionizing and monitoring (automated) data pipelines and micro services
* IAAS: Use terraform to build, change and version infrastructure cloud resources
* Optimized cost for running cloud services
I help customers to onboard on Cloud, build data pipeline platform, implement business requirements from PoC to production
Please check out our presentation for Data + AI Summit Europe 2020.
Our presentation in video Monitoring Half a Million ML Models, IoT Streaming Data, and Automated Quality Check on Delta Lake
Work

Senior Data Engineer Consultant
Eneco
July 2023 - Present
Responsibilities:
- Lead and mentor a team of data engineers, ensuring high-quality delivery of data solutions.
- Design, build, and optimize data pipelines to extract data from various sources,
load it into the data lake and data warehouse, and ensure efficient data processing and storage.
- Migrate and onboard existing data pipelines to run on Databricks,
leveraging its features for automatic pipeline scheduling and performance monitoring.
- Propose and design new data architecture solutions in response to evolving business requirements,
ensuring scalability, performance, and security.
- Participate in hands-on development, troubleshooting, and optimization of data pipelines and workflows.
- Collaborate with cross-functional teams, including Data Scientists, Analysts, and other stakeholders,
to deliver high-impact data solutions that drive business value.
Tech stack: Databricks, Kedro, Snowflake, Kafka, Azure, Airflow, DBT, K8s, Python, Java
Senior Data Engineer Consultant
ING Nederland
Aug 2021 - June 2023
Responsibilities:
- Embrace Cloud technology so that Business can focus on their core purpose.
- Take part evaluating right tools for business need.
- From brainstorming, PoC to put data ingestion streaming pipelines to production.
- Take part in requirement analysis, architecture design decision and hands on implementation.
- Work with collaboration with Google
Tech stack: Google Cloud Platform (IAM, VPC, Artifact Registry, Cloud Monitoring, Compute Engine,GCS, PubSub, Dataflow, BigQuery). Azure DevOps, Azure KeyVault, Kafka
Senior Software Engineer / Data Engineer
Eneco/Quby
Jan 2019 - Jul 2021
Responsibilities:
- Design, develop, maintain (build it and run it) real-time streaming and batch processing jobs and services, data pipelines following Kappa and Lambda architecture.
- Manage highly scalable (peta-bytes scale) multi-tenant data lakes and data processing infrastructure.
- IAAS: Use terraform to build, change and version infrastructure cloud resources
Tech stack: AWS (IAM, VPC, S3, SQS, SNS, Kinesis Data Streams, Beanstalk, API Gateway, Cloudwatch, DynamoDB), Databricks Notebook, Apache Spark
Java Developer
Quby
Mar 2016 - Dec 2018
Working as a backend developer at Quby (later merged with Eneco), the company behind Toon
that makes your home smart.Toon provides you insight into your energy consumption,
control your heating, lighting, smoke detectorsand smart plugs on the go.
Toon also provides you insight of you Solar energy production.
Using Toon App, you can control your energy appliance from anywhere. You can even program your thermostat andschedule holiday mode temperatures.
Responsibilities:
- Develop new features based on business requirements.
- Containerized backend services and horizontal scalable.
- Develop new features based on business requirements.
- Expose Toon API for 3rd party integration.
- Implemented several backend services for user onboarding, providing information and notification.
- Write automated tests for regression and load test
- Implemented CI/CD deployment pipelines
- Use Mesos/Marathon for container orchestration
- Organize/participate hackathon(s)
Software Engineer Consultant
Cimsolutions B.V.
Feb 2012 - Feb 2016
Client: Nederlandse Spoorwegen (NS)
Software Engineer
Jul 2014 - Feb 2016
OV-Chipkaart (OVCP) is one of the core business module of NSR. On an average, more than 1million people travel by train daily.
As number of transactions are increasing, complexities in different business modules are also increasing.
As a result,NS would like to redesign and implement its Back-office system using an Enterprise Service Bus
which will result in cost savings and will improve flexibility and scalability.
Responsibilities:
- Requirement Analysis, design and develop proof of concepts
- Develop components using Java EE 6 and integrate using Enterprise Service Bus
- As a team, we deliver from PoC to Production of backoffice system
Client: Vanderlande
Test Automation Engineer
Sep 2013 - May 2014
Vanderlande is a global company that specializes in automated material handling systems,
including conveyor belts, for various industries such as airports, warehouses, and distribution centers.
Worked as a TAE for conveyor belts functional automation.
Client: Nederlandse Spoorwegen (NS)
Software Engineer
Jun 2013 - Aug 2013
Implemented backend of "NS Groepsticket" functionality
Client: Netherlands Aerospace Centre (NLR)
Software Engineer
Jul 2012 - Jan 2013
Worked on MVCNS Aircraft Noice detection simulation backend development
Senior Software Engineer
Grameen Solutions
Oct 2009 - Dec 2011
Software Engineer
Domain Technologies
2006 - 2009
How to build scalable pipeline
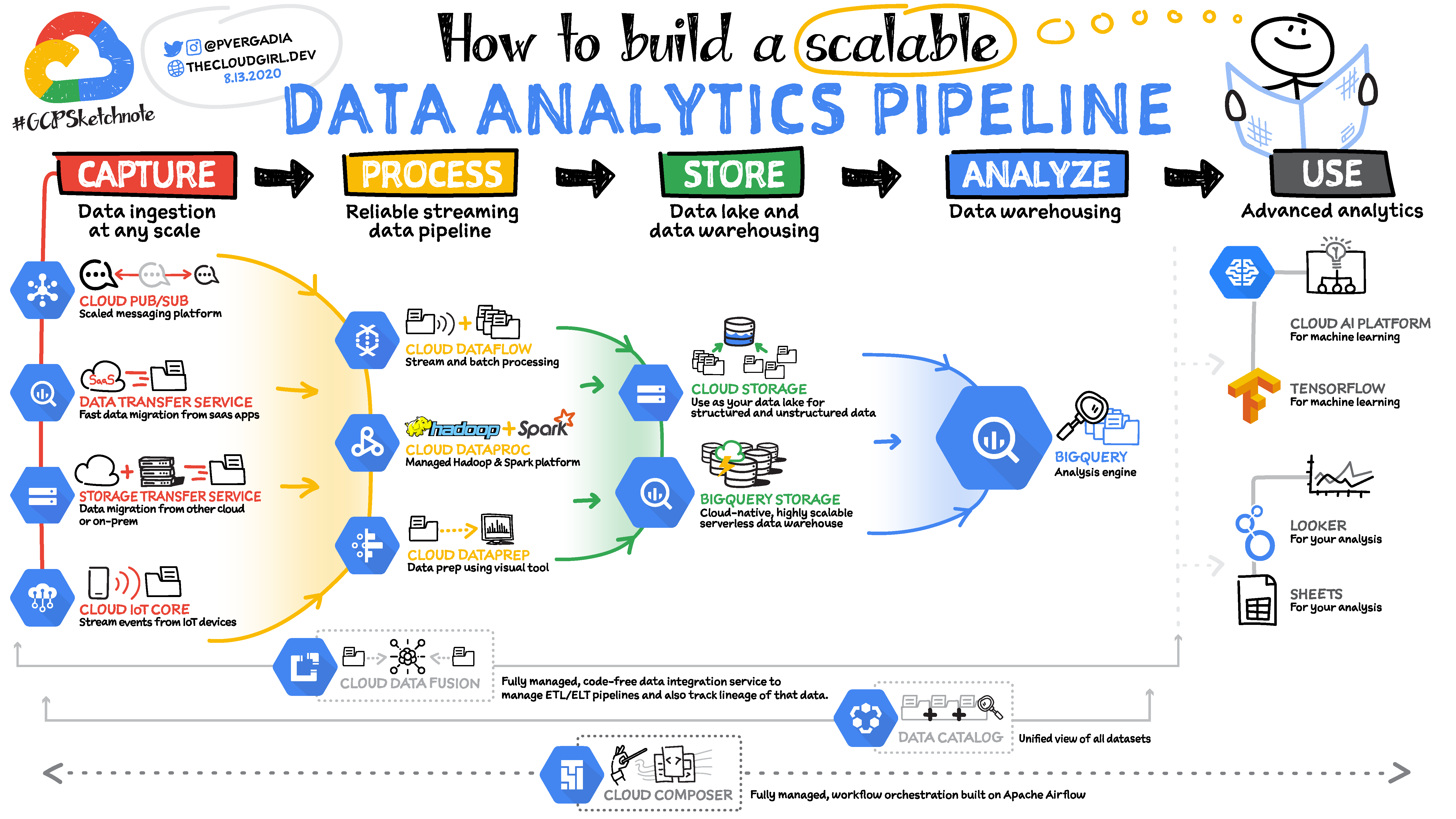
To create a scalable analytics pipeline in Google Cloud Platform (GCP), you can leverage various services and tools available.
Here is a high-level overview of the steps involved in building a scalable analytics pipeline in GCP:
Data Ingestion/Capture: Begin by ingesting data from various sources into GCP. You can use services like Cloud Storage, Pub/Sub, or Data Transfer Service to bring data from on-premises systems, external sources, or other cloud providers into GCP.
Data Processing: Once the data is ingested, you need to process it to extract insights. GCP offers several options for data processing, such as:
- Cloud Dataflow: A fully managed service for real-time and batch data processing. Dataflow can handle large-scale data transformations and supports multiple programming languages.
- Dataproc: A managed Apache Hadoop and Spark service. You can use it for distributed processing of large datasets with tools like Apache Spark or Apache Flink.
- BigQuery: A serverless data warehouse and analytics platform that supports running SQL queries on large datasets. BigQuery can directly process structured and semi-structured data, making it suitable for analysis and aggregation tasks.
Data Storage: Store the processed data in appropriate storage solutions based on your requirements:
- BigQuery: Store structured and semi-structured data in BigQuery tables for further analysis.
- Cloud Storage: Use Cloud Storage for storing raw or processed data in object format. It provides durability, scalability, and accessibility to other GCP services.
- Firestore, Cloud Spanner, or Cloud Bigtable: These are other database options you can consider based on your specific needs.
Data Analysis: Analyze the stored data to gain insights and build reports or visualizations. You can use the following tools for data analysis in GCP:
- BigQuery: Perform complex analytics and run SQL queries directly on BigQuery tables.
- Data Studio: Create interactive dashboards and reports using a drag-and-drop interface. Connect Data Studio with BigQuery or other data sources.
- Looker: A comprehensive business intelligence platform for data exploration and visualization. Looker integrates with BigQuery and other data sources to provide powerful analytics capabilities.
Data Visualization and Reporting: Visualize your analysis results and generate reports for decision-making purposes. GCP offers various tools for data visualization, including:
- Data Studio: Create customized, interactive dashboards and reports using data from BigQuery or other supported data sources.
- Looker: Build comprehensive visualizations and reports using Looker's intuitive interface.
Finally, Monitoring and Optimization : Continuously monitor and optimize your analytics pipeline for performance and cost-efficiency.
Use GCP tools like Cloud Monitoring, Cloud Logging, and Cloud Trace to monitor your pipeline components and identify bottlenecks or issues.
Please note that building a scalable analytics pipeline is an iterative process. You may need to refine and enhance your pipeline based on changing requirements, data volumes, or analytical needs.
About

Lorem ipsum dolor sit amet, consectetur et adipiscing elit. Praesent eleifend dignissim arcu, at eleifend sapien imperdiet ac. Aliquam erat volutpat. Praesent urna nisi, fringila lorem et vehicula lacinia quam. Integer sollicitudin mauris nec lorem luctus ultrices. Aliquam libero et malesuada fames ac ante ipsum primis in faucibus. Cras viverra ligula sit amet ex mollis mattis lorem ipsum dolor sit amet.
Elements
Text
This is bold and this is strong. This is italic and this is emphasized.
This is superscript text and this is subscript text.
This is underlined and this is code: for (;;) { ... }. Finally, this is a link.
Heading Level 2
Heading Level 3
Heading Level 4
Heading Level 5
Heading Level 6
Blockquote
Fringilla nisl. Donec accumsan interdum nisi, quis tincidunt felis sagittis eget tempus euismod. Vestibulum ante ipsum primis in faucibus vestibulum. Blandit adipiscing eu felis iaculis volutpat ac adipiscing accumsan faucibus. Vestibulum ante ipsum primis in faucibus lorem ipsum dolor sit amet nullam adipiscing eu felis.
Preformatted
i = 0;
while (!deck.isInOrder()) {
print 'Iteration ' + i;
deck.shuffle();
i++;
}
print 'It took ' + i + ' iterations to sort the deck.';
Lists
Unordered
- Dolor pulvinar etiam.
- Sagittis adipiscing.
- Felis enim feugiat.
Alternate
- Dolor pulvinar etiam.
- Sagittis adipiscing.
- Felis enim feugiat.
Ordered
- Dolor pulvinar etiam.
- Etiam vel felis viverra.
- Felis enim feugiat.
- Dolor pulvinar etiam.
- Etiam vel felis lorem.
- Felis enim et feugiat.
Icons
Actions